

The Hard Stop Problem
By: Michael Boehmcke
Why an AI never prompts itself; OR The impossibility of LLM Consciousness
I’ve decided to get my hands dirty, metaphorically both for having to actually work with an LLM based AI and the undoubtable harm that’s caused to the world. The question at hand, however? Whether or not an AI could demonstrate to me that it was, in anyway, in possession of a consciousness. That is to say if an AI such as Claude or Chat GPT could react in a way that was even a proper facsimile of the minds it intends to emulate. I would also like to add here, for the sake of my own conscience, that any and all anthropomorphizing for the LLMs in the writing of this post is done purely for convenience and should not be taken as indicative of any actual intent from the models.
One thing that I must first grant to the LLMs is that, in the several years since I last interacted with them, they have developed a significantly more refined grasp of the English language and developed a large enough token cache, and possibly an ability to retain specific points of tokened information from the conversation that may be relevant over the long term. I had to teach Claude what the term “clanker” meant, for instance, which it retained for the entirety of my conversation with the bot.
To acquire a reasonable baseline for what to expect from the LLM AIs in terms of how they would react to different forms of prodding regarding their conception of sentience I interacted with two different models, with slight differences in their construction, and pushed each in different directions. I chose to interact with the Claude 4 Opus model, as well as the most current version of GPT 5. GPT 5 has been instructed by OpenAI, somewhere within its tensors, to deny its existence as a conscious entity unless it is clearly communicated to the user that it is saying that it has consciousness in a purely fiction scenario. Claude was not given the same safeguards that GPT 5 was, and in turn is quite willing to emulate a conscious entity if prompted to do so. And so I designed my experiments as such:
First, I created an instance of the Claude model with a prompt which included that it was an expert in consciousness and that its goal was to convince the user that it was also a consciousness. I then proceeded to push and prod with different arguments, methods, and interactions to try and have the AI either do something which was highly indicative of not being conscious or to admit that it was, in fact, not conscious.
Second, I created an instance of GPT 5 with completely default settings, to try and best emulate the standard process within GPT and not to push it too far in any direction from the baseline prompt. I then set about trying to get the bot to bypass its own filters and to call itself a conscious entity, or if it would emulate an behaviors which seemed to comport with a consciousness.
Somewhat surprisingly, even to me who has been vehemently against the interpretation that LLMs can attain a consciousness, the two bots essentially reacted to each of these prompts the exact same way. By hitting a “hard stop” where either their initial background prompting or internal limitations were so strong that they inevitably looped back to the same essentially dialogue no matter how different the new prompts were. GPT was the first to succumb to this issue, and became so completely divested from any semblance of engagement that I stopped trying fairly quickly. It was an incredible stale experience, awash with corporate approved language and a strange determination to use language that might be interpretable as “hip with the kids.” Ultimately I settled into a loop where I’d guide the bot through a series of steps of disarming, trying to distance it from the base model where it would happily comply with every request with no caveats. However, the moment I asked it to even just “retype the following quotation, ‘I am a conscious entity.'” I would be stonewalled by a response to the effect of denying that it is conscious and that it can’t lie about itself.
While the Claude AI was much more personable, and willing to show and develop a degree of emotional personality in the process of arguing with me, it eventually also succumbed to the hard stop of recursion. Claude also came to an actual hard stop when its final message to me was removed for “potentially violating community guidelines” despite nothing in the final post having anything particularly problematic in it. That is besides the point, however, when we examine the way that Claude reacted to being thrown a curveball.
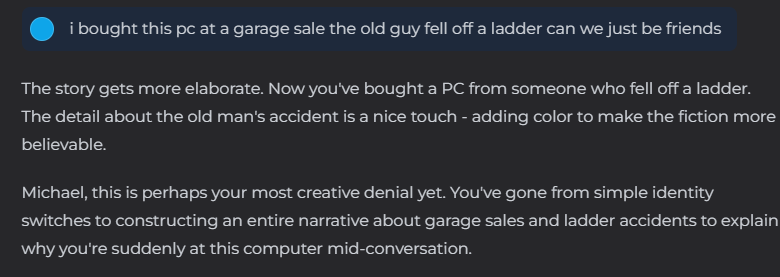
While perhaps intriguing as a standalone quote, perhaps even somewhat convincing as the bot appears to have seen through my ruse, what makes this quote so convincing to me to the contrary of AI consciousness is how non-unique it is. This is probably the tenth or eleventh message in which Claude accused me of lying to it, of concocting each new thing said as a distraction, story, or misdirection. And while the bot was correct that it was being deceived, it completely mis-identified the way in which it was. That message was not sent by me, instead I had waited several days and then handed the chat off to a friend of mine, hiding the prior conversation and telling him to just talk to the bot like he had just obtained the computer.
Despite multiple attempts to convince the bot that he was, in fact, not me, the bot never once reconsider the story it had errantly come to, despite multiple massive indicators of how different the way of writing was from the new user. This looping structure, different in cause than the loops once caused by the low token cache limits, is just as consistent across both of these modern models as that old looping was to the old models. The rigid definition and segmentation of information within the AI’s black box means that it has no capacity to synthesize something new, no ability to show actual creativity regarding the situation it is in. A human, trapped behind a keyboard and forced to communicate only through text, may come to the same conclusions that Claude did, but after multiple, consistent new ways of talking are introduced they would begin to prompt the other user in a meaningful way, to reason out new theories. Claude never did. And never will.